ПРОДУКТЫ
|
|
 GritTec's Speaker-ID: Текстонезависимая идентификация дикторов по голосу
GritTec's Speaker-ID: Текстонезависимая идентификация дикторов по голосу
Обзор
GritTec's Speaker-ID: Automatic Text Independent Speaker Identification (Version 4.10) - технология
текстонезависимой идентификации/верификации дикторов по голосу. Технология предназначена для автоматической
голосовой идентификации или голосовой верификации неизвестной аудиозаписи в отложенном режиме путем парного сравнения с образцами
аудиозаписей известных дикторов.
Разработанный алгоритм голосовой идентификации независит от языка и основан на попарном сравнении спектральных характеристик голоса неизвестного диктора со спектральными характеристиками записи целевого голоса диктора. |
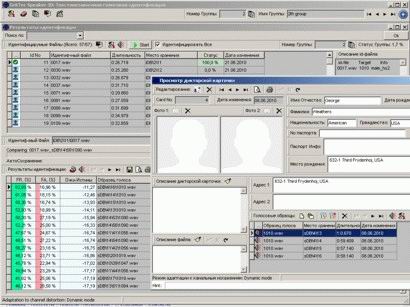
Рис. GritTec Speaker-ID: The mobile client.
|
Вычисление спектральных характеристик выполняется с учетом динамического определения уровня канальных искажений, внешних помех и шумов, присутствующих в анализируемом речевом сигнале с голосом диктора. Это позволяет компенсировать канальные искажения и
воздействия внешних помех при сравнении спектральных характеристик,
вносимых в исходный речевой сигнал. Чувствительность идентификации
определяется уровнем установки порогов вероятности ошибок 1-го (FRR) и 2-го (FAR) рода.
В настоящий момент движек GritTec's Speaker-ID реализован в программном решении с GUI интерфейсом -
GritTec Speaker-ID: The mobile client.
Применение
- Для автоматической идентификации неизвестного голоса по фонограммам телефонных переговоров;
- В системах с повышенным уровнем безопасности, например, компьютерный доступ к информации, доступ к которой ограничен заданным кругом лиц.
Достоинства
- Операции с низким уровнем SNR;
- Быстрая адаптация к канальным искажениям и внешним шумам;
- Минимальная длительность речевого сигнала для получения индивидуальных особенностей голоса – не менее 15 секунд;
- Минимальная длительность речевого сигнала для проведения идентификации или верификации – не менее 7 секунд;
- Надежность идентификации дикторов не менее 90% при сравнении пары речевых сигналов передаваемых по одному и тому же каналу связи;
- Надежность идентификации дикторов не менее 85% при сравнении пары речевых сигналов передаваемых по разным каналам связи;
- Поддержка мульти-потоковой идентификации или мульти-потоковой верификации;
- Поддержка программных лицензионных ключей или аппаратных с использованием USB ключа (см. Описание поставки пакета SDK);
- Поддержка лицензионных ключей, в зависимости от которых зависит количество целевых голосовых образцов, которые одновременно могут использоваться в одном потоке голосовой идентификации;
- Поддержка лицензионных ключей, в зависимости от которых зависит количество одновременно запущенных потоков голосовой идентификации или количество одновременно запущенных потоков голосового обучения;
- Простота встраивания в целевое приложение.
Требования к сигналу
- Формат сигнала: 16-bits linear;
- Частота оцифровки: 8 kГц;
- Отношение сигнал-шум (SNR), не менее 10 db;
- Полоса частот сигнала: 300-3400 Гц или лучше.
Доступность
- Демонстрационные программы под MS Windows x86/x64, Linux x86/x64 платформы;
- Программный комплекс с GUI интерфейсом на базе GritTec Speaker-ID: The mobile client;
- Пакеты SDK для разработчиков под MS Windows x86/x64, Linux x86/x64 платформы с программным или аппаратным (USB ключ) видом лицензирования.
- объектный код ANSI C/C++;
- Java обложка для запуска с окружением Java SE (x86/64) Runtime Environment;
- Java скрипты для запуска с окружением Node.js (x86/64).
Достижения
Для оценки точности GritTec's Speaker-ID движка в режиме голосовой верификации использовалось голоса 25 целевых
дикторов (12 - мужчин, 13 - женщин) для английского языка. Каждый целевой диктор
обучался раздельно как для CELL канала, так и для VOIP канала. Общее
количество файлов используемых для обучения было 50, из них 25
файлов - для CELL канала и 25 файлов для VOIP канала. Каждый
обучаемый файл содержал 12 фраз случайного набора цифр (от 0 до 5)
общей длительностью ~ (40-50) секунд.
Общее количество файлов используемых для верификации в CELL и VOIP
каналах было 31950, где 30195 файлов с голосами дикторов обманщиков, и 1755 файлов с голосами целевых дикторов. Каждый
верифицируемый файл содержал 1 фразу случайного набора цифр (от 0 до 6) с общей длительностью ~ (4-6) секунд.
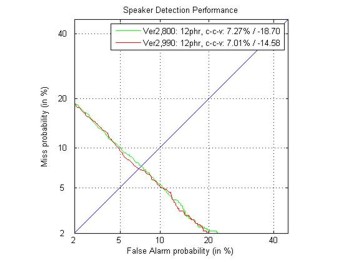
Ниже показаны графики DET кривых и EER (Equal Error Rate) ошибок
результов верификации для CELL и VOIP каналов.
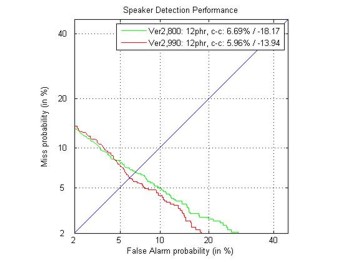 
EER: 5,96% (обучение на CELL, верификация на CELL);
EER: 7.01% (обучение на CELL, верификация на CELL и VOIP);
EER: 3.91% (обучение на VOIP, верификация на VOIP).
EER: 8.11% (обучение на VOIP, верификация на CELL и VOIP);
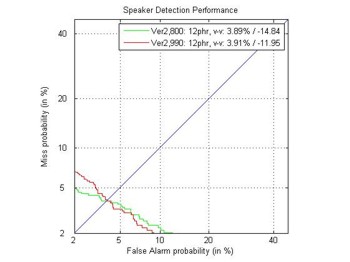 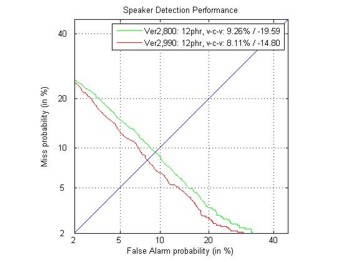
Все результаты были получены для GritTec's Speaker-ID (Версия 2,90) в сравнение с версией 2,80.
Online Shopping and Free Downloads
- Все программы имеют бесплатный период работы с момента их инсталяции;
- Чтобы продолжить использовать программы после завершения бесплатного периода, вы можете купить end-user лицензию;
- Чтобы купить end-user лицензию, кликните 'Buy Now' под соответствующим продуктом.
|
Программное обеспеченье текстонезависимой идентификации дикторов по голосу c графическим интерфейсом. Предназначена для автоматической голосовой идентификации неизвестной аудиозаписи в отложенном режиме. Данный продукт будет полезен криминалистическим центрам, МВД, call центрам и банкам, целью которых является тектонезависимая голосовая идентификация неизвестных аудио фонограмм в отложенном режиме. Узнать больше. |
|
Цена: 2000.0 у.е.
 |
 MS Windows x86 or x64. MS Windows x86 or x64.
Формат входного сигнала:
Windows PCM, A/mu-Law Wave, Microsoft ADPCM (MS ADPCM), Intel ADPCM (IMA
ADPCM), Microsoft ACM GSM 6.10 (ACM Waveform). |
|
Данная программа представляет собой bash скрипт для демонстрации автоматической голосовой идентификации личности по аудио файлам в консольном режиме. Программа может быть использована на стороне BackEnd сервера для проведения автоматической голосовой идентификации аудио файлов в отложенном режиме. |
|
Цена: 5000.0 у.е.
|
MS Windows x86/x64.
 x64/x86. x64/x86.
Формат входного сигнала:
Windows PCM (8 kГц, 16-bits linear). |
|
Данная программа представляет собой Java скрипт для демонстрации автоматической голосовой верификации или голосовой идентификации личности по аудио файлам c помощью Java SE (x64/x86) окружения. Программа может быть использована в банках на стороне BackEnd сервера для дополнительной проверки личности клиентов по голосу. |
|
Цена: -
Узнать детали |
MS Windows x86/x64.
 Java SE x64/x86. Java SE x64/x86.
Формат входного сигнала:
Windows PCM (8 kГц, 16-bits linear). |
|
Данная программа представляет собой Java скрипты для демонстрации автоматической голосовой верификации по аудио файлам c помощью Node.js (x64/x86) окружения. Программа может быть использована в банках на стороне BackEnd сервера для дополнительной проверки личности клиентов по голосу. |
|
Цена: -
Узнать детали |
MS Windows x86/x64.
 Node.js x64/x86. Node.js x64/x86.
Формат входного сигнала:
Windows PCM (8 kГц, 16-bits linear). |
|
Данная программа представляет собой bash скрипт для демонстрации автоматической голосовой идентификации личности по аудио файлам в консольном режиме. Программа может быть использована на стороне BackEnd сервера для проведения автоматической голосовой идентификации аудио файлов в отложенном режиме. |
|
Цена: -
Узнать детали |
 Linux x86 or x64. Linux x86 or x64.
Формат входного сигнала:
Windows PCM (8 kГц, 16-bits linear). |
Для получения дополнительной информации Отправьте запрос.
|
|
|
|